In artificial neural networks, an activation function defines the output of a node given an input or set of inputs. Without them, a neural network is effectively just a linear regression model. By introducing non-linearity, activation functions allow networks to learn complex, high-dimensional functions.
1. Sigmoid Function
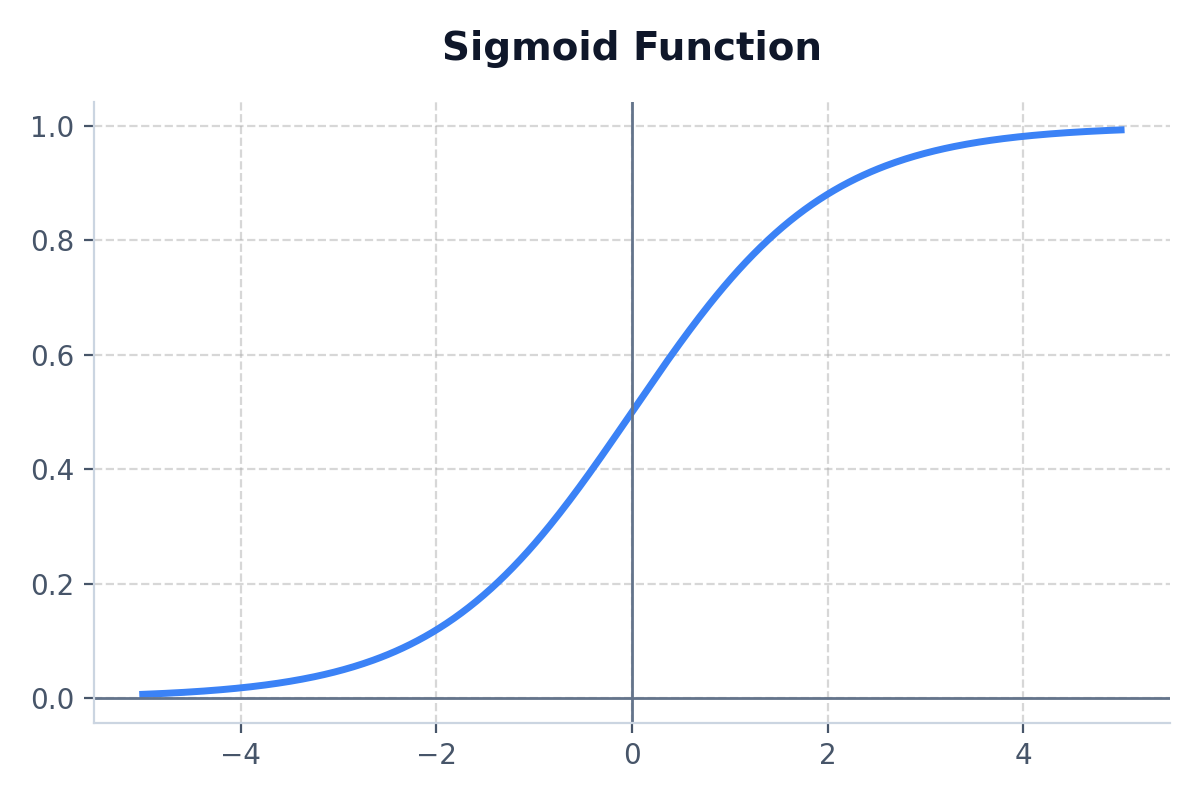
The Sigmoid function maps any real value into a range between 0 and 1. It forms an 'S' shaped curve.
- Formula: f(x) = 1 / (1 + e^-x)
- Best Use Case: Ideal for binary classification models (e.g. outputting a probability between 0 and 1) in the final output layer.
- Drawback: Suffers from the "vanishing gradient" problem for very large or very small inputs.
2. Tanh (Hyperbolic Tangent)
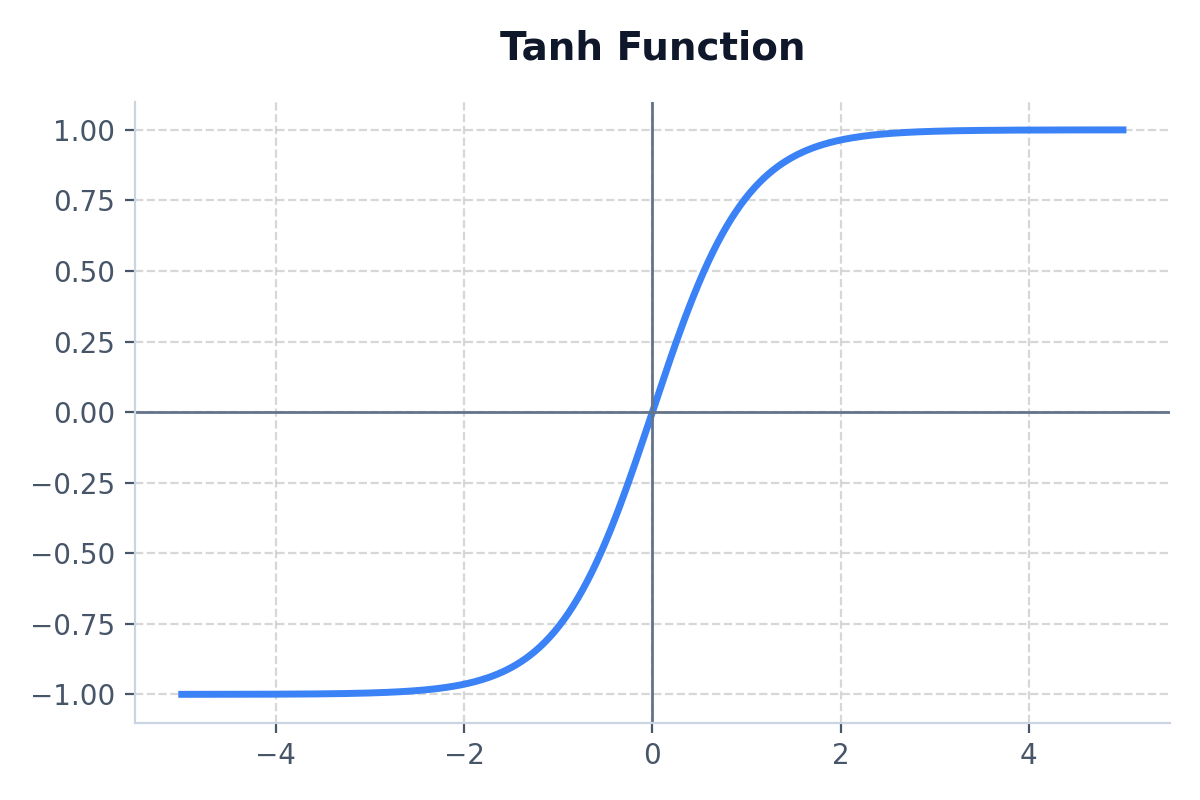
Tanh is incredibly similar to Sigmoid, but it maps values between -1 and 1. This means it is zero-centered, making optimization much easier in hidden layers.
- Best Use Case: Preferred over Sigmoid for hidden layers in Recurrent Neural Networks (RNNs).
3. ReLU (Rectified Linear Unit)
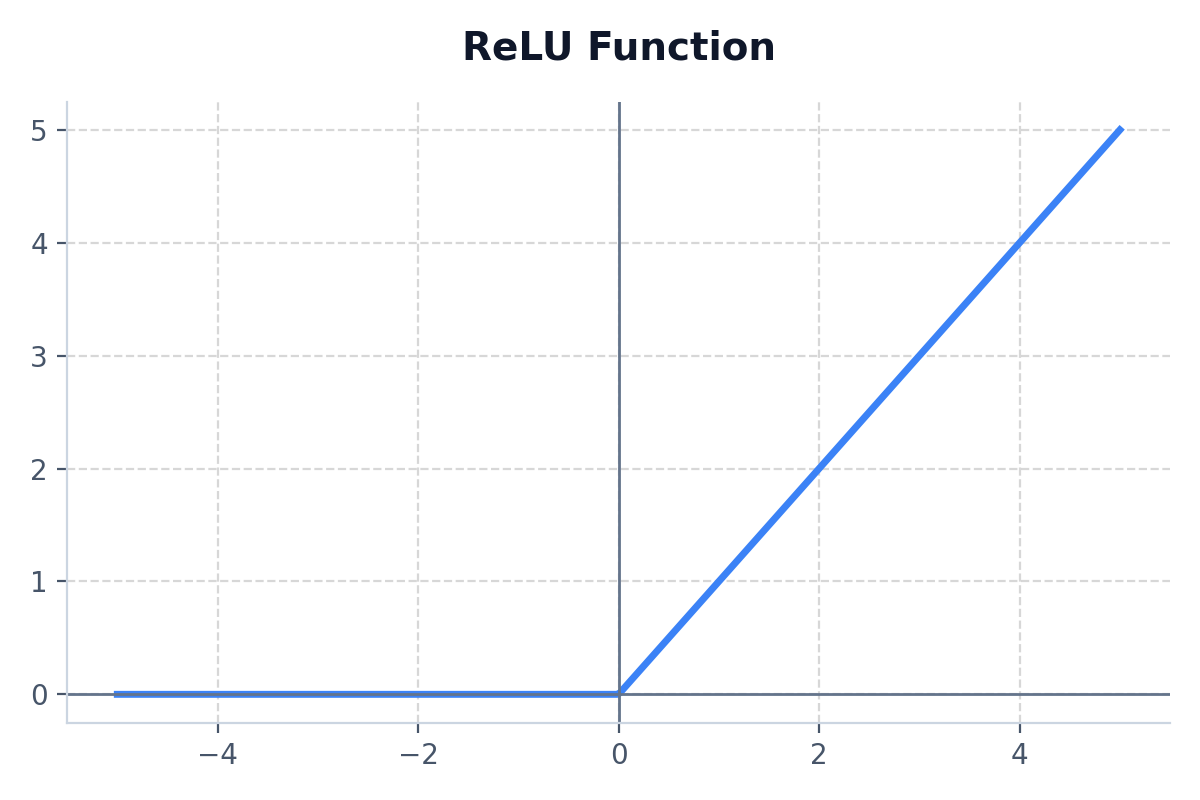
ReLU is the most popular activation function today. If the input is positive, it outputs the input directly. If it is negative, it outputs zero.
- Formula: f(x) = max(0, x)
- Best Use Case: Default activation function for hidden layers in Convolutional Neural Networks (CNNs) and deep MLPs.
- Drawback: The "Dying ReLU" problem, where neurons predicting negative numbers eternally output 0 and never update their weights again.
4. Leaky ReLU
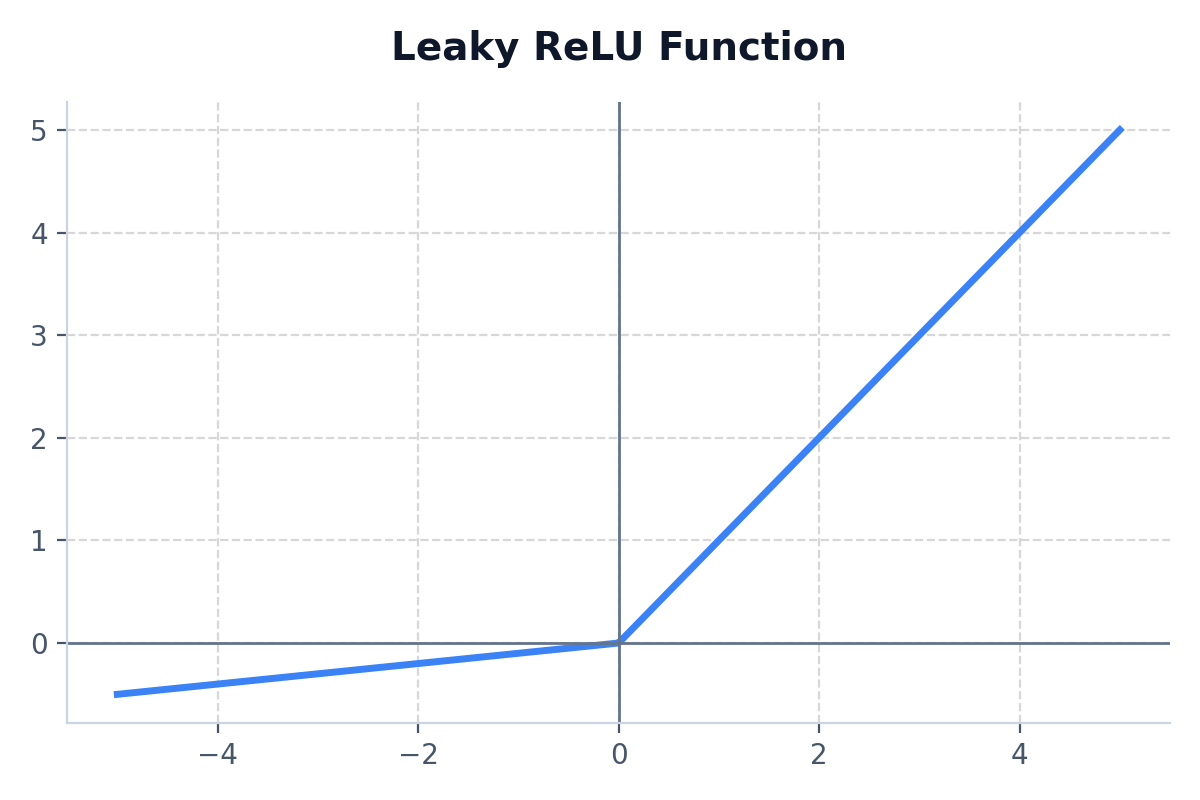
An attempt to fix the Dying ReLU problem. Instead of outputting a flat 0 for negative values, it outputs a very small gradient (like 0.01x).
- Best Use Case: Use when your standard ReLU network suffers from dead neurons.
5. Identity (Linear)
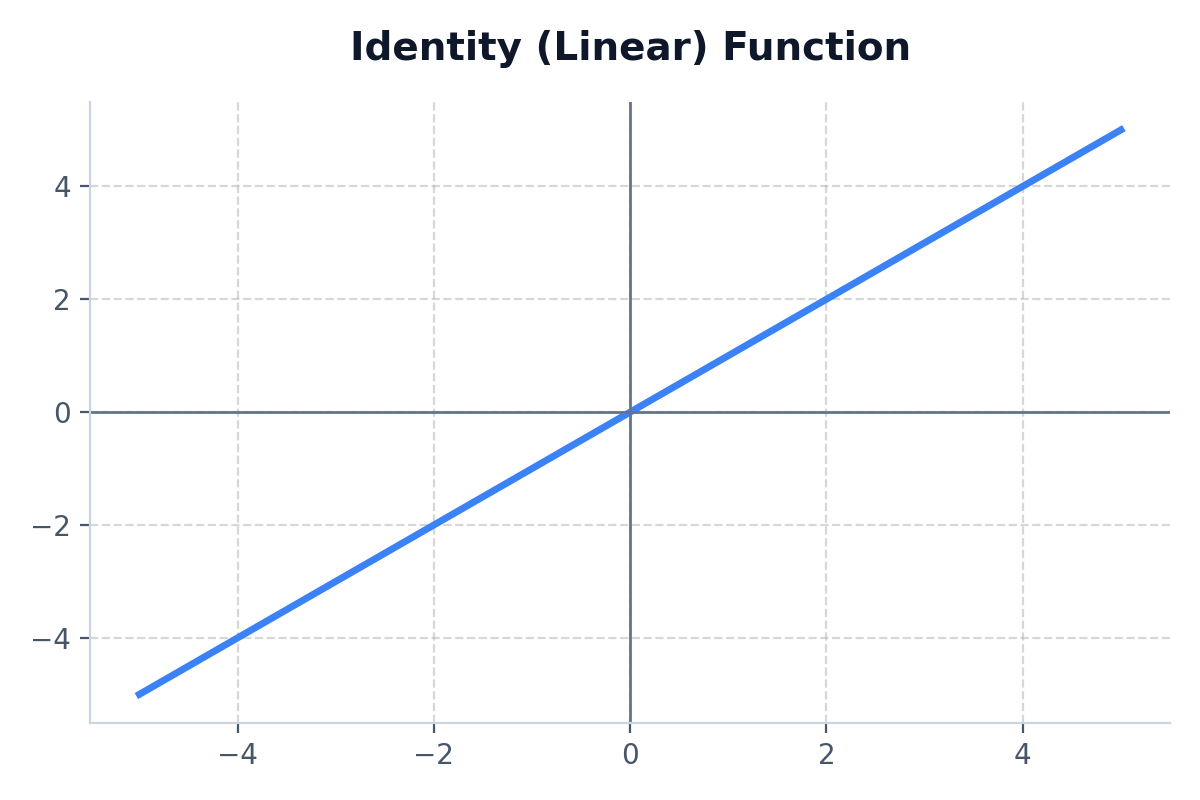
The output is exactly the same as the input. It provides no non-linearity.
- Best Use Case: Only used in the very last output node of a regression neural network (where you predicting a continuous number like house price).
6. Gaussian
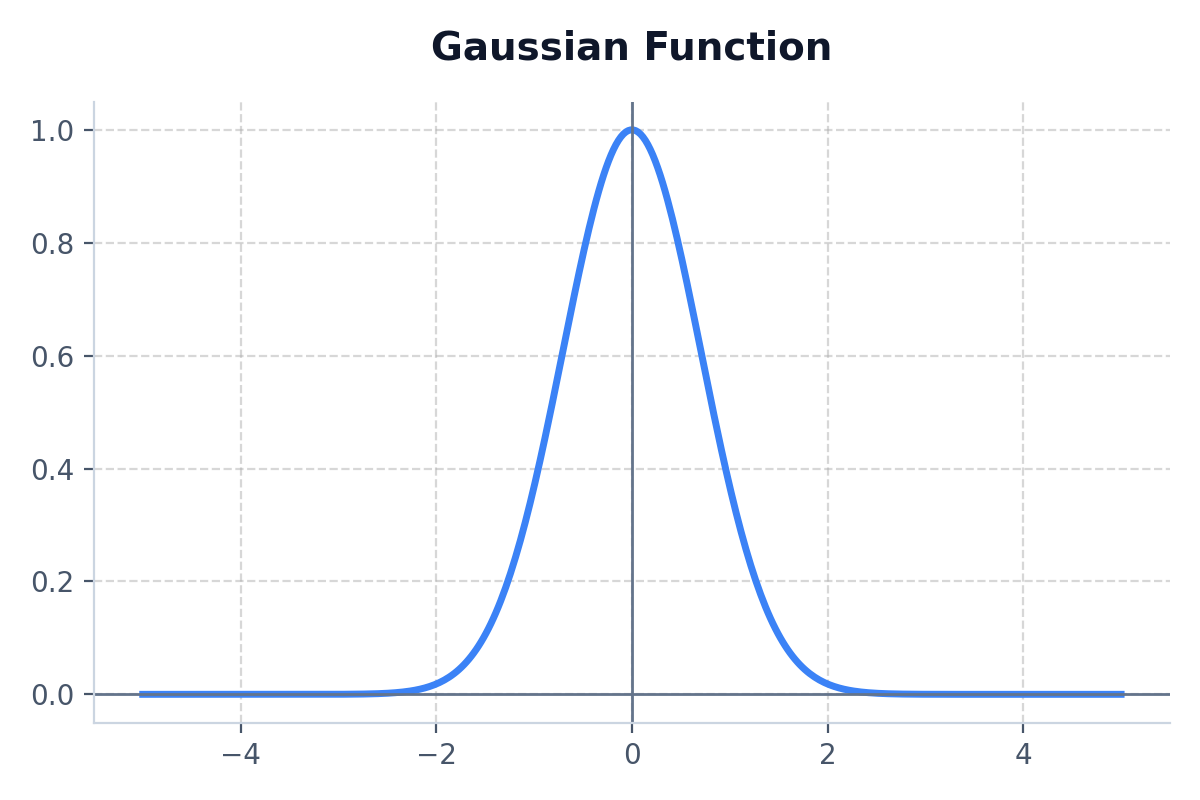
Produces a bell-curve shape, yielding a high output only when the input is near 0.
- Best Use Case: Extremely niche. Primarily used in Radial Basis Function (RBF) networks.
7. Binary Step
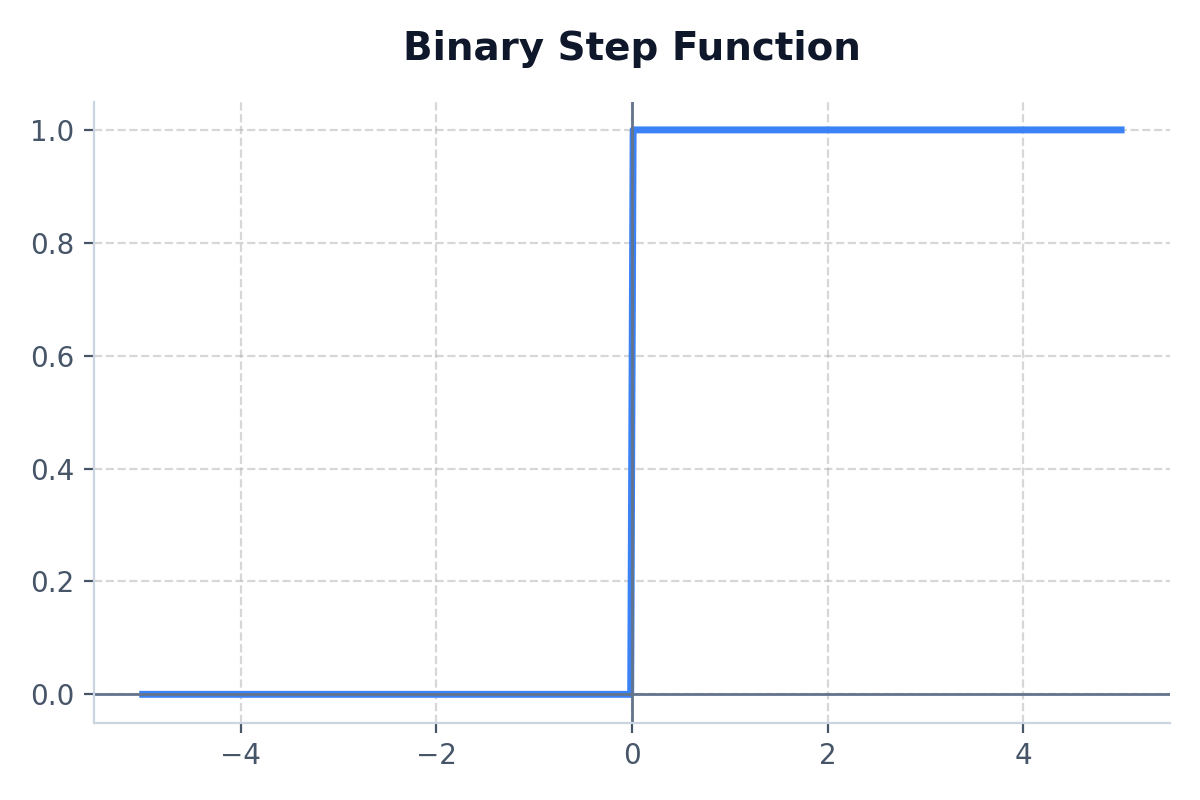
A simple threshold gate: outputs 1 if input is greater than zero, and 0 if it isn't.
- Best Use Case: Early theoretical perceptrons. Never used in modern backpropagation because its derivative is constantly 0.
Python Example: Activation Functions in NumPy
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def relu(x):
return np.maximum(0, x)
def leaky_relu(x, alpha=0.01):
return np.where(x > 0, x, alpha * x)
# Test array
x = np.array([-2.0, -1.0, 0.0, 1.0, 2.0])
print("Sigmoid:", sigmoid(x))
print("ReLU:", relu(x))
print("Leaky ReLU:", leaky_relu(x))